


Data often possesses underlying shapes and geometric structures that can be harnessed to model robust data distributions. The Fisher–Rao metric exemplifies this approach by providing a Riemannian framework that respects and exploits the intrinsic geometry of probability distributions.
This article is the second entry in our series on Information Geometry, building on the previous piece titled Geometry of Closed Form Statistical Manifolds



🎯 Why this matters
Purpose: Optimization, inference, representation learning, and robustness in machine learning benefits from understanding the geometry of distribution of input data. The Fisher-Rao metric is a direct application of Riemannian Geometry and a valuable component of the Geometric Deep Learning toolkit.
Audience: Data scientists and engineers involved in modeling statistical distribution and improving the robustness and generalization of their models.
Value: Gain practical experience with the Fisher information metric and Fisher–Rao distance on statistical manifolds using the PyTorch and Geomstats libraries. Geomstats includes built‑in support for Fisher–Rao manifolds.
🎨 Modeling & Design Principles
Overview
The first article [ref 1] introduced the Fisher (Riemannian) metric for four basic distributions—Exponential, Geometric, Poisson, and Binomial—and demonstrated its use in computing the exponential and logarithm maps.
This follow-up explores core geometric concepts in greater depth, including the Fisher-Rao distance between distribution parameters and the inner product of vectors in the tangent space
Fisher Metric
A Fisher-Riemann manifold is a differentiable manifold M whose points correspond to probability distributions p(x∣θ) from a statistical model parameterized by θ∈Θ⊂Rn, and which is equipped with the Riemannian metric g [ref 2]
The Fisher information metric for a continuous probability density function p is defined (outer product formulation).
Given that the expectation and differentiator operators can be interchanged. the metric can also be computed as (Hessian formulation)
📌 Although not a strict rule, data scientists favor the outer product formulation for the Fisher-Rao metric while the Hessian formulation is most commonly used by mathematicians.
The Fisher information induces a positive semi-definite metric on the parameter manifold, allowing the use of tools from differential/Riemannian geometry
The Fisher metric is invariant under sufficient statistics, making it intrinsic to the statistical model.
Fisher-Riemann manifolds are Riemannian manifolds whose metric is derived from the Fisher information metric—a central concept in information geometry. They arise naturally when treating families of probability distributions as smooth geometric objects [ref 3].
⚠️ The terminology found in the literature can be confusing. Strictly speaking the Fisher-Riemann manifold is the manifold of distributions equipped with the Fisher-Rao metric. It is also called the Fisher information manifold or the statistical manifold.
Fisher-Rao Distance
The Fisher–Rao distance quantifies the dissimilarity between two probability distributions on a statistical manifold equipped with the Fisher information metric. It represents the length of the shortest path (geodesic) connecting two points (distributions) θ1 and θ2 on this manifold.
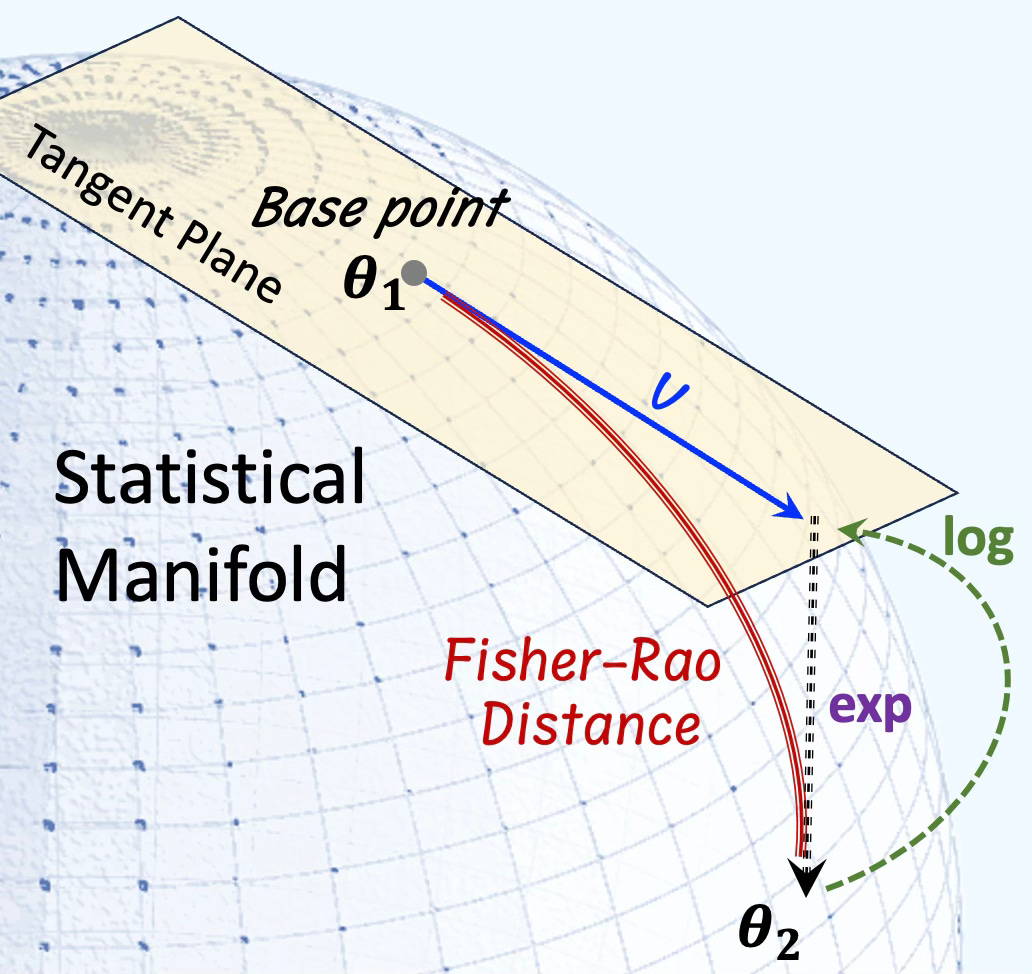
Fig. 1 Visualization of the Fisher-Rao distance (Geodesic) of a statistical manifold
Given γ(t) a smooth curve parameterized with t, the distance between θ1 and θ2 on a statistical manifold is defined as:
This formulation captures the intrinsic geometry of the statistical manifold, with the Fisher information matrix acting as the Riemannian metric tensor.
📌 Computing the Fisher–Rao distance involves solving the geodesic equations derived from the Fisher information metric. However, some closed-form distributions have explicit expressions. This article illustrates the Fisher information matrix with single parameter distributions.
Inner Product of Vectors/Parameters
This inner product measures the infinitesimal change in the log-likelihood function, capturing the sensitivity of the probability distribution to changes in the parameters.
Given two vectors u and v at a point θ on a statistical manifold defined as
The inner product of under the Fisher-Rao metric at a point θ on a statistical manifold is computed as
The norm is easily computed as
📌 We use the covariant indexes for the Fisher metric and contra-variant indexes for the vector coordinates.
Closed-form distributions
Exponential Distributions
Given a rate parameter θ > 0 the probability density function of the exponential distribution is
with the Fisher-Rao metric g computed as
The formula for the distance between θ1 and θ2 is
The inner product of two vectors u, v at parameter θ is computed as
Geometric Distributions
Given the probability of success p at each trial, the probability of success after k trials is defined as
with the Riemannian metric g
and the distance between two points p1 and p2 on the Geometric manifold is
The inner product of two vectors u, v at point p is computed as
Poisson Distributions
Given a Poisson distribution with the expectation λ (rate parameter) events for a specific interval, the probability of k events in the same interval is
with the Fisher metric g defined as
and the distance between two parameters λ1 and λ2
The inner product of two vectors u, v at a point λ is computed as
Binomial Distributions
Binomial Distribution has a closed form in the case number of draws is fixed. Given a probability distribution of success p in a sequence of n independent experiments (or number of draws).
with the Fisher metric g:
The distance between two points p1 and p2 on the Binomial manifold given a fixed number of experiments n
📌 Many complex, high-dimensional statistical manifolds—particularly multivariate ones—lack closed-form expressions for fundamental geometric components like the Fisher metric, exponential map, or geodesic paths.
In such cases, practitioners must resort to numerical techniques, including finite-difference ODE solvers (e.g., Runge–Kutta), geodesic shooting or path-based solvers, and various interpolation methods to approximate these quantities faithfully.
⚙️ Hands-on with Python
Environment
Libraries: Python 3.12.5, PyTorch 2.5.0, Numpy 2.2.0, Geomstats 2.8.0
Source code: geometriclearning/geometry/information_geometry/fisher_rao.py
Evaluation code for this article: geometriclearning/play/fisher_rao_play.py
The source tree is organized as follows: features in python/, unit tests in tests/, and newsletter specific evaluation code in play/.
To enhance the readability of the algorithm implementations, we have omitted non-essential code elements like error checking, comments, exceptions, validation of class and method arguments, scoping qualifiers, and import statements.
🔎 Setup
⏭️ This section guides you through the design and code.
We leverage the implementation of the statistical manifold by subclassing CFStatisticalManifold [ref 1]. This implementation relies on the Geomstats library to generate the random point for each of the statistical manifolds [ref 4 & 5].
⚠️ Computing the Fisher metric in Geomstats requires either the Autograd or PyTorch backend. This is simply accomplished by setting the environment variable GEOMSTATS_BACKEND.
The constructor takes the following arguments
The statistical manifold, info_manifold.
Upper and lower bounds of the interval for the random variable.
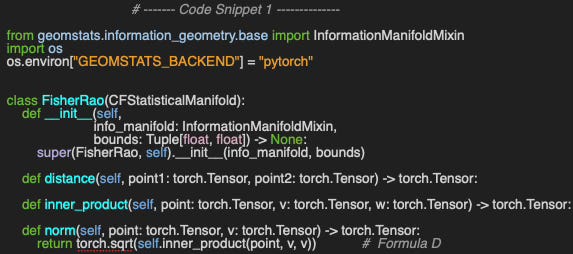
The norm (Formula D) is computed directly from the inner product of a vector by itself.
📈 Evaluation
Let’s implement the analytics formula to compute the distance for each of the statistical manifolds as a direct application of the formulas described in the previous section.
The first step is to generate n_samples random points on the statistical manifold, stats_manifold for the 4 univariate distributions with the relevant interval bounds (Code snippet 3).
👉 The evaluation code is available at geometriclearning/play/fisher_rao_play.py

Output:
ExponentialDistributions samples:
0.2551, 0.3307, 0.6764, 0.6447, 0.1431, 0.4753, 0.2847, 0.8912
GeometricDistributions samples:
0.1476, 0.4375, 0.5165, 0.5825, 0.1973, 0.6029, 0.5535, 0.2298
PoissonDistributions samples:
18.2592, 1.5876, 19.5412, 14.2694, 10.6064, 15.5452
BinomialDistributions samples:
0.6866, 0.7174, 0.3928, 0.5364, 0.1098, 0.1504Next we evaluate the distance of two random points of each of the 4 statistical manifolds (Code snippet 4).

Output
ExponentialDistributions d(0.8440, 0.8492) = 0.0062
GeometricDistributions d(0.0131, 0.4401) = 0.0487
PoissonDistributions d(18.5083, 11.2240) = 1.9038
BinomialDistributions d(0.6957, 0.4829) = 1.2344We visualize the probability density function for these 2 randomly generated points (single parameters) for each of the 4 statistical manifolds.
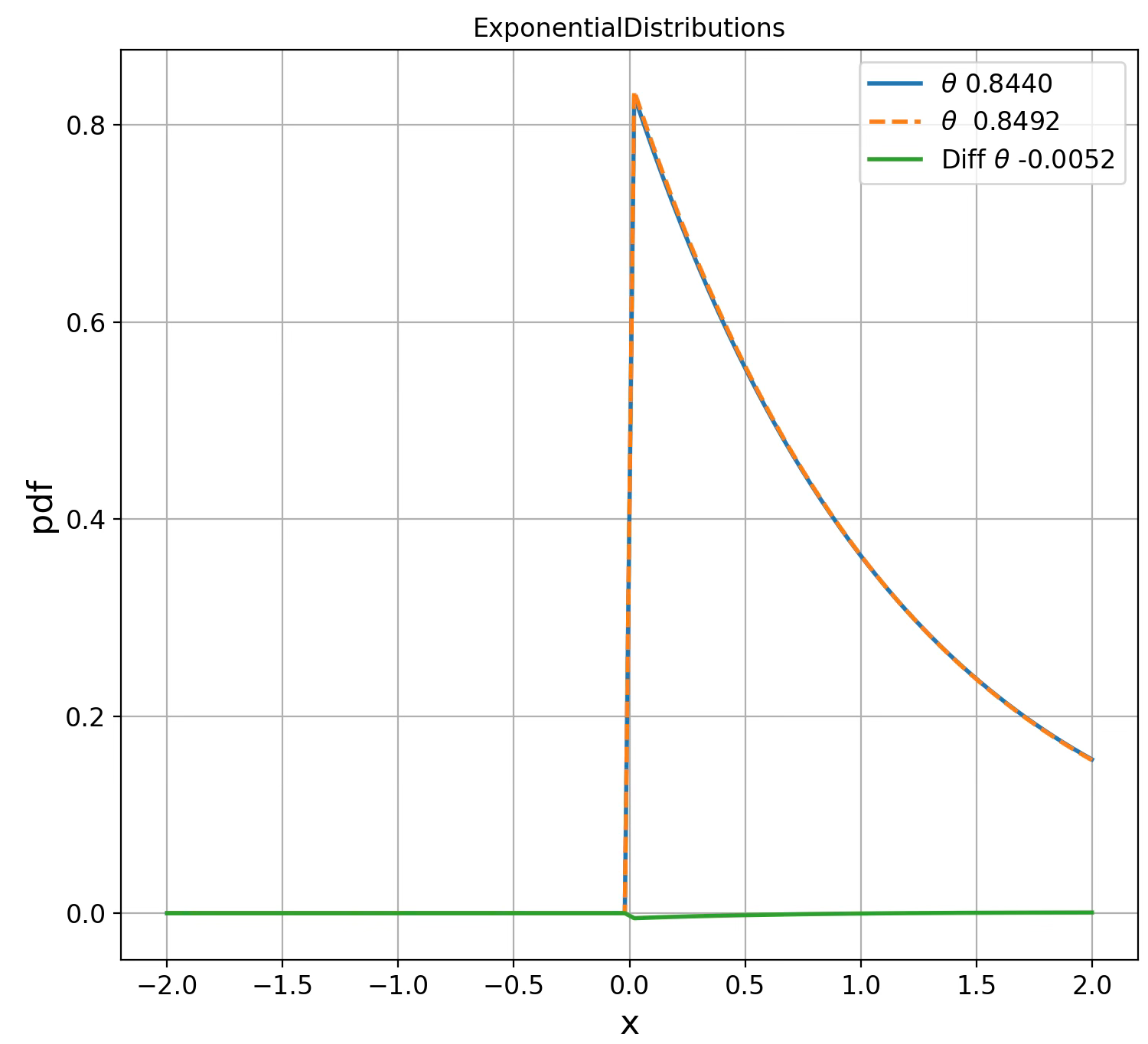
Fig. 2 Visualization of Exponential distribution for two parameters on Fisher manifolds
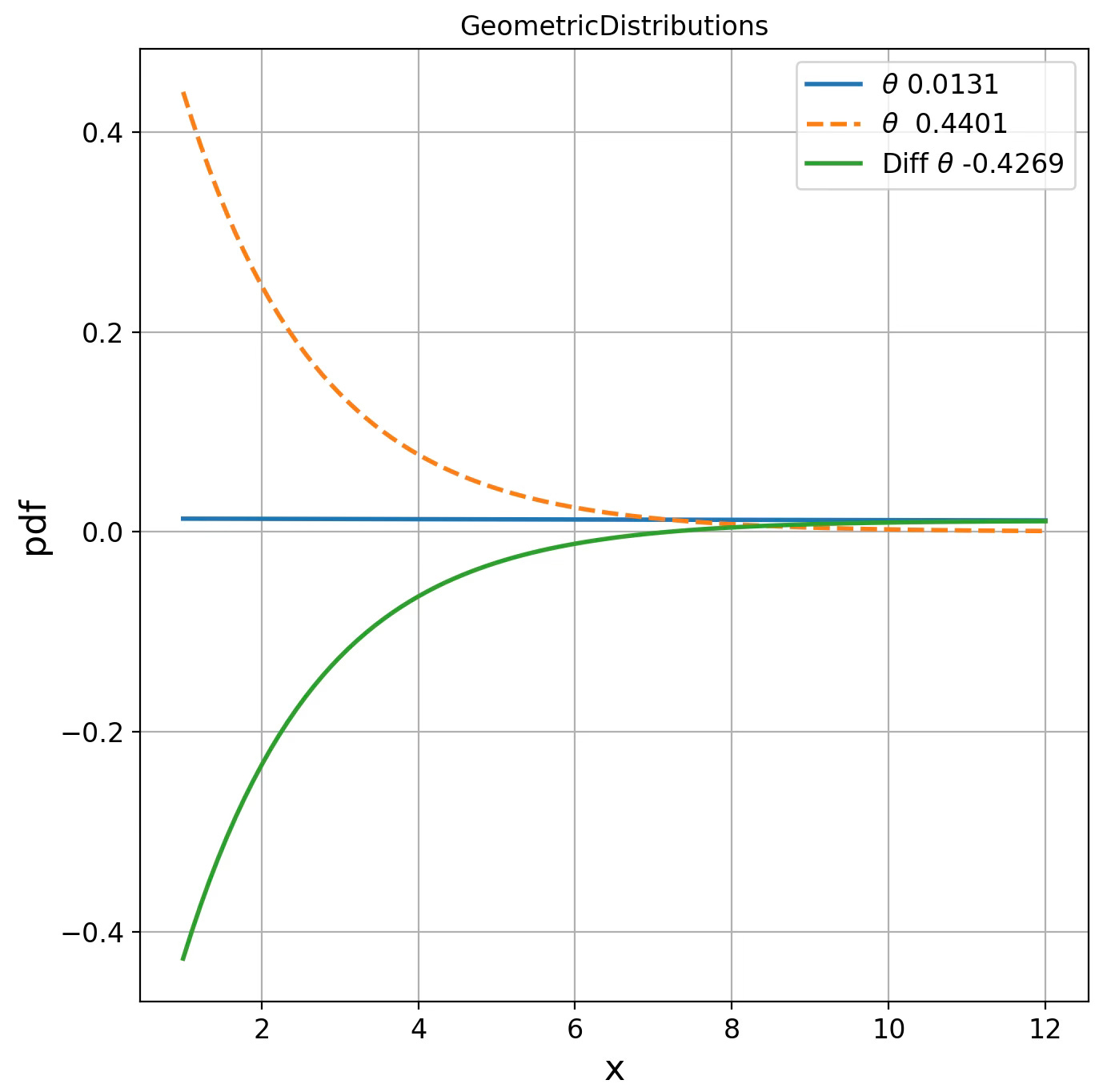
Fig. 3 Visualization of Geometric distribution for two parameters on Fisher manifolds
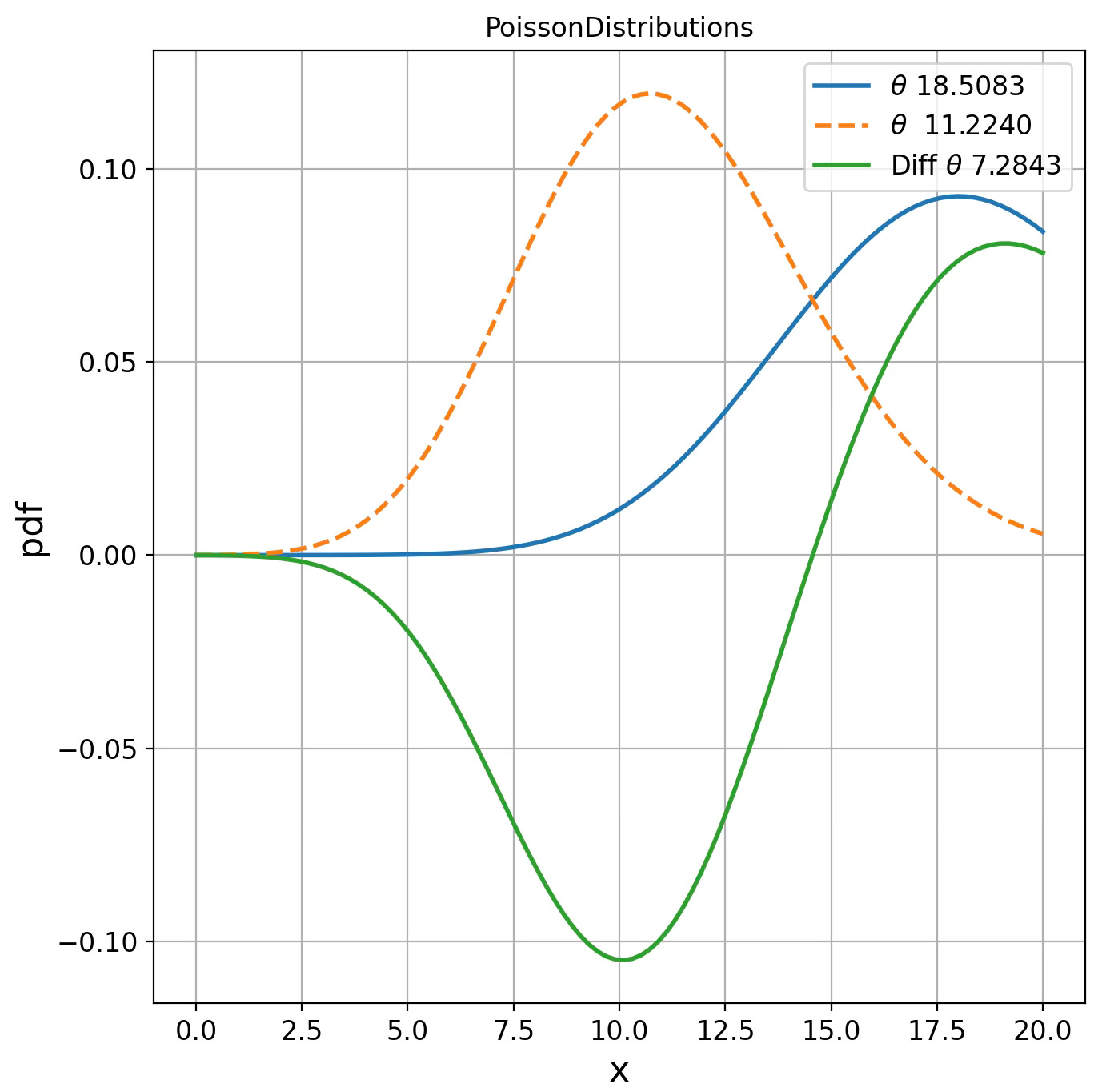
Fig. 4 Visualization of Poisson distribution for two parameters on Fisher manifolds
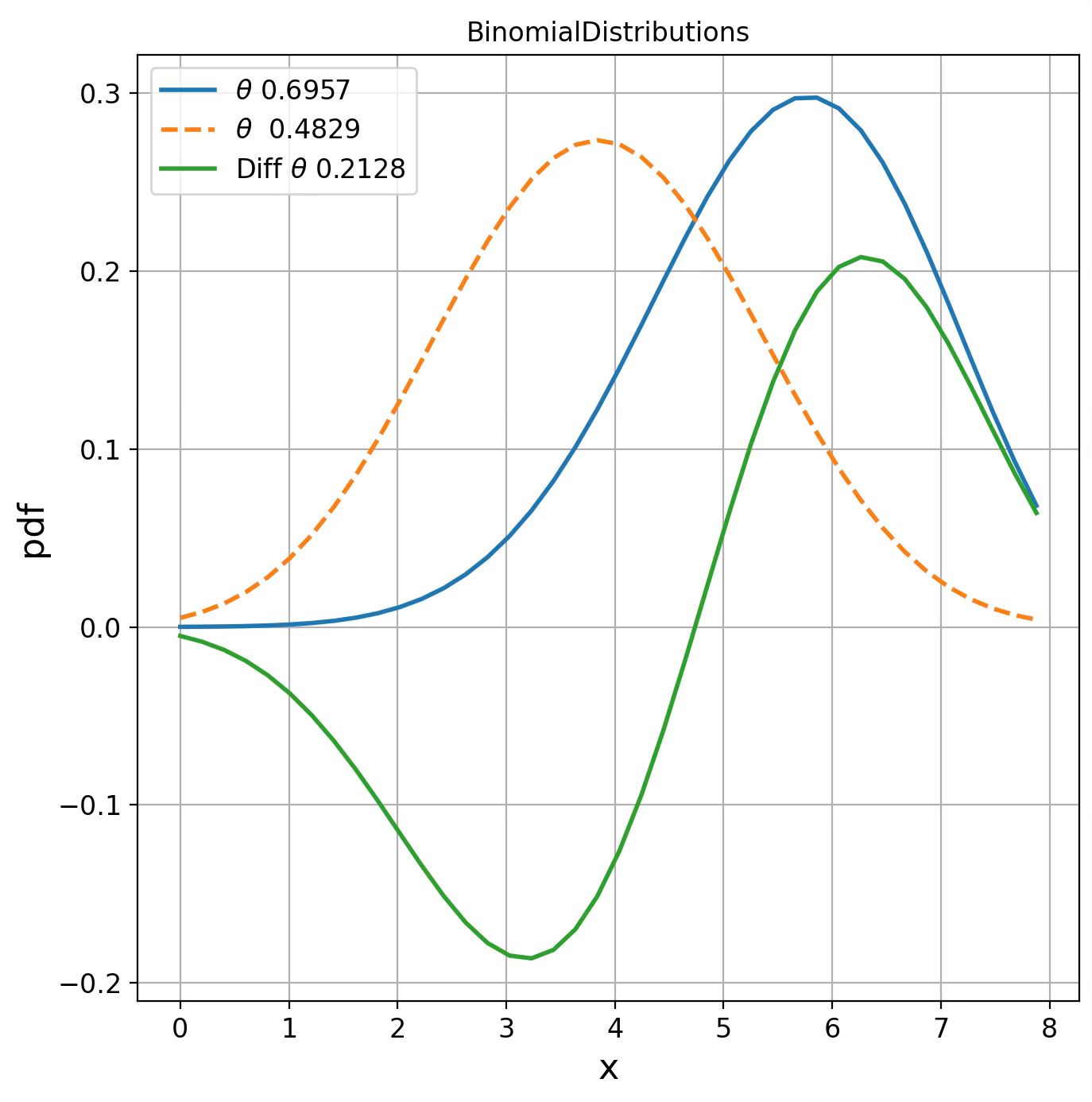
Fig. 5 Visualization of Binomial distribution for two points on Fisher manifolds
Implementing the inner product between two vectors, v and w, at a given point on each of the four statistical manifolds is a straightforward application of the formula introduced in the previous section (Code snippet 4).
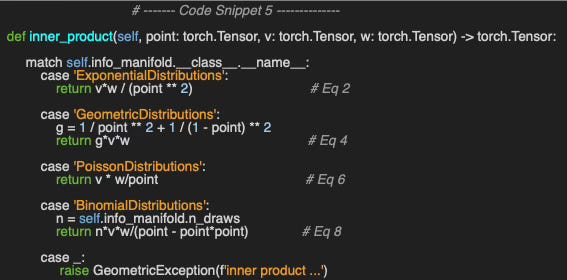
Let’s compute the inner product of two vectors/parameters u, v as follows
u=1.0, v=-1.0
u=1.0, v=0.0
u=2.0, v=0.5

Output
ExponentialDistributions 1.0 dot -1.0 = -3.600
GeometricDistributions 1.0 dot -1.0 = -8.240
PoissonDistributions 1.0 dot -1.0 = -0.157
BinomialDistributions 1.0 dot -1.0 = -221.076
ExponentialDistributions 1.0 dot 0.0 = 0.000
GeometricDistributions 1.0 dot 0.0 = 0.000
PoissonDistributions 1.0 dot 0.0 = 0.000
BinomialDistributions 1.0 dot 0.0 = 0.000
ExponentialDistributions 2.0 dot 0.5 = 1.180
GeometricDistributions 2.0 dot 0.5 = 78.837
PoissonDistributions 2.0 dot 0.5 = 0.128
BinomialDistributions 2.0 dot 0.5 = 42.672As expected, the inner product of the vectors +1.0 and –1.0 is negative, while that of +1.0 and 0.0 is 0.0.
Finally, we proceed to compute the norms of vectors on the four different statistical manifolds.
ExponentialDistributions Norm(0.5) = 1.186
GeometricDistributions Norm(0.5) = 1.468
PoissonDistributions Norm(0.5) = 0.182
BinomialDistributions Norm(0.5) = 3.898
ExponentialDistributions Norm(1.0) = 1.398
GeometricDistributions Norm(1.0) = 2.893
PoissonDistributions Norm(1.0) = 0.385
BinomialDistributions Norm(1.0) = 16.802The value of the norm reflects the curvature at a given point. of the manifold.
🧠 Key Takeaways
✅ We delve deeper into closed-form statistical manifolds by examining both the Fisher–Rao distance and the inner product on their tangent spaces.
✅ Using PyTorch, we directly implement the Fisher information metric, compute distances, and evaluate tangent-space inner products for the exponential, Poisson, geometric, and binomial distributions.
✅ For generating sample points on these manifolds, we leverage Geomstats for convenience and consistency.
📘 References
What is Fisher Information? YouTube - Ian Collings
🛠️ Exercises
Q1: What are the most commonly used numerical integration techniques to compute exponential or logarithm maps of complex statistical manifolds without closed-form?
Q2: Can you write the steps to the Fisher metric formula for the exponential distribution?
Q3: Given the Fisher metric for the Poisson distribution, can you generate the distance between two points on the manifold?
👉 Answers
💬 News & Reviews
This section focuses on news and reviews of papers pertaining to geometric deep learning and its related disciplines.
Paper Review: Analysis of Static & Dynamic Batching Algorithms for Graph Neural Networks D. Speckhard, T, Bechtel, S. Kehl, J. Godwin, C Draxl
Graph Neural Networks (GNNs) are computationally expensive to train, making them strong candidates for batching techniques commonly used in standard deep learning models. This paper evaluates two batching strategies—static and dynamic.
Libraries such as JGraph (JAX-based) and PyTorch Geometric support dynamic batching, while TensorFlow offers both static and dynamic batching.
Dynamic Batching
Implementation varies across libraries but follows a common approach:
Estimate padding constraints for each batch (size is a multiple of 64) by sampling a subset of the dataset.
Iteratively add graphs to the batch until the padding limit is reached.
Static Batching
This method adds a fixed number of graphs per batch and then pads them to a predefined size.
A common trick is to introduce dummy graphs so that the total number of nodes and edges is a power of 2, optimizing memory utilization.
Experimental Setup
Environment: 4x A100 GPU with NVLINK using:
Datasets: QM9 (chemical properties) & AFLOW (material properties)
Models: SchNet (Graph Convolutional Network) & MPEU (Message-Passing Neural Network)
Key Findings
Dynamic batching is slower than static batching due to the overhead of managing varying padding constraints.
Static batching techniques, particularly, batching with total nodes and edges as multiples of 64 and batching with totals as powers of 2n achieved the lowest average training times.
Dataset characteristics and batch size tuning can improve performance by over 33%.
Patrick Nicolas is a software and data engineering veteran with 30 years of experience in architecture, machine learning, and a focus on geometric learning. He writes and consults on Geometric Deep Learning, drawing on prior roles in both hands-on development and technical leadership. He is the author of Scala for Machine Learning (Packt, ISBN 978-1-78712-238-3) and the newsletter Geometric Learning in Python on LinkedIn.